Bootstrap#
Suppose you have a sample of 100 units. You want to construct a confidence interval of your sample mean. How can you bootstrap to construct a sampling distribution?
Show code cell content
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
import scipy
from tqdm import tqdm
sns.set(rc={'figure.figsize':(11.7,8.27)})
Fake Data:#
x = np.random.chisquare(15, 100)
Bootstrap:#
Repeatededly draw samples of size X (e.g. 40) from your sample of 100, with replacement.
For each sample, compute the mean.
def bootstrap(x, n_samples = len(x), n_resamples = 9999):
return [
np.mean(np.random.choice(x, size=n_samples, replace=True))
for _ in range(n_resamples)
]
sample_means = bootstrap(x)
sns.kdeplot(sample_means)
plt.axvline(np.mean(sample_means), 0,1, color="red")
<matplotlib.lines.Line2D at 0x7fdfb3f27100>
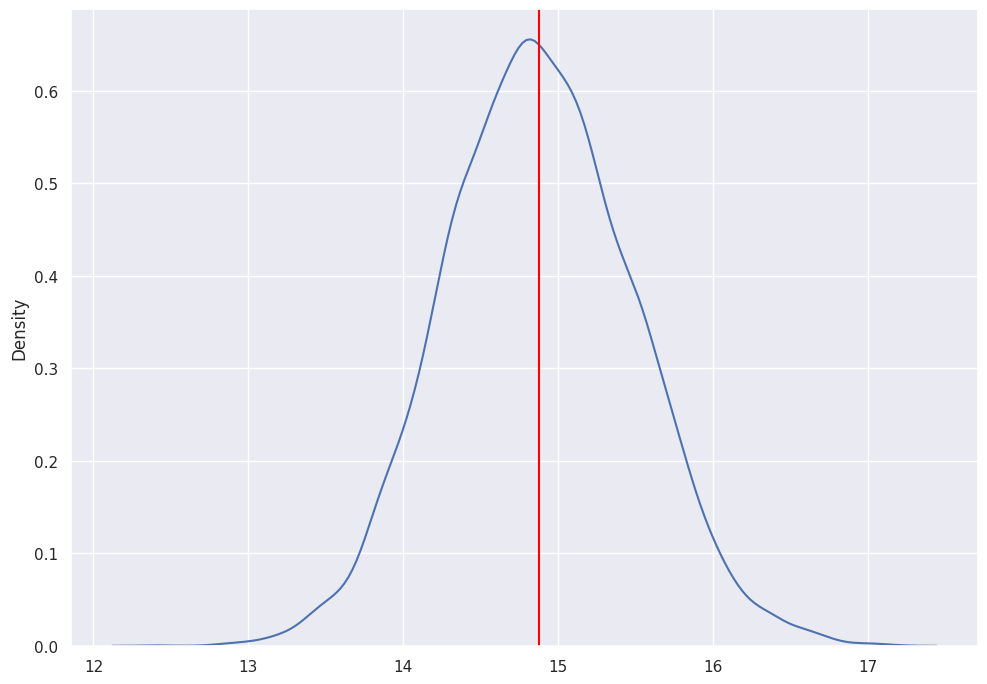
# 95% confidence interval
print(
(
np.quantile(sample_means,0.025),
np.quantile(sample_means,0.975)
)
)
(13.735435939160023, 16.074187786035562)
Bootstrap Using Scipy Stats#
res = scipy.stats.bootstrap((x,), np.mean, confidence_level = 0.95)
res.confidence_interval
ConfidenceInterval(low=13.744242864521835, high=16.158612656104697)